Advances in block propagation
Why does node resource usage matter?⌗
Original bitcoin protocol was very inefficient, sending each transaction twice:
-
gossiped in
INVmessages around the network -
in the next block
This didn’t equate to a doubling of bandwidth for the nodes but this was unfortunately because nodes were being inefficient in many other ways, too! For example, using ~38 byte INV messages to notify peers of a new ~200 byte transaction ("I’ve heard about this new trasnaction 0xDEAD…BEEF, have you heard about it?") means that a lot of bandwidth is used on the gossip itself.
Avoiding sending transactions to peers twice was calculated to save ~12% of bandwidth at the time, which is not negligible in such an optimised system as bitcoin.
Also the original block propagation mechanism was very burst-y; when a new block was found it would burst (up to) 1 MB block all in one go to all it’s peers.
Latency⌗
An important metric to consider is the latency to distribute blocks around the network. In particular, to all of the hash power. This is a concern for 2 reasons:
-
If it takes a long time to propagate a block, relative to the interval time between blocks, then the network will see more short-length forks. Confirmed transactions can get re-orged out, "false confirmations".
Bitcoin has a block interval of 10 minutes, if we ever wanted to lower this, block propagation times would have to be improved first.
-
If blocks are slow to propagate mining is turned more "race-like" and less "lottery-like", as it’s supposed to be; with 10% of hashrate you should expect to mine 10% of the blocks. If you don’t know about the latest blocks you can extend on them.
Why is progress in mining bad⌗
If blocks take a long time to propagate miners with more hash rate gain a disproportionate advantage. They are effectively "starting the race" (to find the next block) earlier than other miners which sees them find more blocks, become more profitable and able to afford more hash rate and further the centralisation effect.
This is not particularly related to the connection speed of the miners — even with a slow connection, if you have a lot of hash rate you can still gain from this effect. This argument was commonly put to Chinese miners (behind the Great Firewall) in the past.
This problem is difficult to obseve directly and can be actively hidden, see the selfish mining attack posited by these Cornell researchers in 2013 for example.
Selfish mining attack⌗
In the selfish mining attack it is posited that a miner with a lot of hash power will become more profitable if they withhold blocks they find from the rest of the network for a short period of time, whilst trying to always remain one block ahead of the other miners.
This appears to work because, when the selfish miner reveals their longer chain of blocks, the nodes on the network will detect it has more accumulated proof-of-work and re-org the other chain out. This causes the miners who mined the now-defunct chain to both lose money on the re-orged block, but also to have apparently wasted money trying to mine the last block altogether.
Binance have a good explanation of the selfish mining attack on their website.
Why won’t miners solve block propagation issues⌗
-
Bad propagation can be advantageous for (larger) miners.
-
Miners are not protocol development specialists and instead of addressing a protocol issue directly, they’ve historically:
-
joining a larger pool to increase profitability (increasing centralisation)
-
extending chains blindly, mining without verifying.
This invalidates a key SPV client assumption, that miners are fully validating blocks and transactions.
-
-
Miners not to blame, they’re just following incentives best.
Sources of block latency⌗
-
Creating block templates for candidate blocks (was taking up to 3 seconds pre 0.12!)
-
Dispatching the template to hashers
-
Hearing a solution back from hashers
-
Distribute solution to first-level peers
-
Time to serialise data across the wire, protocol and TCP round trips
-
Average bitcoin data speed between miners was on average 750 kbit/s
-
-
Round trips are bad on high-latency links (e.g. through the great firewall)
-
-
First peer validating (fixed in 0.14/0.15, better caching etc.)
-
Distributing solutions to second-level peers
Original Bitcoin block relay protocol⌗
┌──────────────────────────────────────────────────────────────────────┐
│ ┌───────────────┐ ┌───────────────┐ │
│ │ │ │ │ │
│ │ Node A │ │ Node B │ │
│ │ │ │ │ │
│ └───────────────┘ └───────────────┘ │
│ │ │ │
│ │
│ block │ │ │
│──────────────▶ │
│ │ │ │
│ ▼ │
│ ┌───┐ │ │
│ │ │ │
│ │ │ │ │
│ │ │ │
│ │ │ │ │
│ │ │ │
│ │ │ │ │
│ │ │ │
│ │ │ │ │
│ │ │ │
│ │ │ │ │
│ │ │ │
│ └───┘ │ │
│ │ │
│ │ │
│ │ headers or inv │
│ ───────────────────────────────────────▶│ │
│ │ │
│ │ │
│ │ │
│ getdata │ │
│ │◀─────────────────────────────────────── │
│ │ │
│ │ │
│ │ │
│ │ block │
│ ───────────────────────────────────────▶│ │
│ │ │
│ │ │
│ │ │
└─────────────────────────────────────────────────────────┴────────────┘This relay protocol is nice and simple: a block comes in to A, A sends an INV message, B then issues getdata to ask for the block, and A then sends it to them.
However, a node knows on average 99.953% of the transactions in new blocks before the block arrives. In addition to the round trip in the INV → getdata → block protocol exchange, there are also TCP roundtrips which we need to wait for.
Bloom filtered block relay (2013)⌗
It was observed that BIP 37 filterblock messages could be used to get a block with the already-seen transactions removed to eliminated the duplication overhead.
However, testing in 2013 appeared to show that this slowed down propagation and there were some issues regarding discarded transactions which were still in the filters further complicating things.
Protocols vs Networks⌗
Protocol is only part of the story — a great protocol can’t fix a slow VPS with bad connectivity.
Corallo started a curated public network of nodes which miners could connect to to get low latency. At first it was a network of well-run bitcoin nodes, but in the future the "relay network protocols" being used started to become more developed.
Fast Block Relay protocol (2013-2015)⌗
-
Alice remembers the last 'N' transactions sent to Bob.
-
When a block shows up for Alice to send to Bob, Alice will reference which transactions it contains using a 2 byte index into the "sent trasnactions" ledger, or an escape plus the whole transaction.
-
This requires not full round trips, Alice knows what Bob knows and can send block without asking.
-
However it can have high overhead, especially with multiple peers.
-
Therefore perhaps best for a hub-and-spoke topology network.
-
-
Also requires each peer to send you every transaction (so Bob recieves them from each Alice) to "prepare" for the fast block part of the protocol.
Block network coding (2014)⌗
Some block propagation techniques turned out to be very CPU inefficient, which neutered the propagation gains.
BIP-152 Compact Blocks (2016)⌗
Primary goal was to eliminate double transaction transmission in block relay with the hope of also ofsetting some of the SegWit block size increases. It also achieved lower latency as a side-effect.
Compact blocks used by virtually all nodes in the network today and has two modes:
-
Non high bandwidth
-
High bandwidth
What is a compact block⌗
The idea is to exploit what the other side already knows, without knowing yourself. Roughly you would expect to send to a peer:
-
block_header+txn_count+ 8 bytesalt= 13308 bytes typical -
n_txn* 6 byte "short ID" (48 bits)-
Where a "short ID" =
siphash-2-4(txid, SHA2(header || salt))NoteSiphash was chosen because it is incredibly fast for this type of operation
-
The receving node will hash and scan their mempool to see which transactions it already knows using the shortID matches. Little data is sent but collisions and missses must still be resolved with additional round trips.
Why are hashes salted?⌗
The reason for the salt is so that a troublemaker can’t produce two transactions with the same short ID very easily. A 48 bit collision is relatively easy to compute. If we said for example we used (longer) 8 byte short IDs, 64 bit, then to find a collision would only take ~232 work due to the birthday paradox.
If miners or users could so easily engineer collisions they could selectively impact block propagation on the network.
Salt selection in the compact blocks scheme is taken from the block header of the block that found it, which means it cannot be known ahead of time. It also has an additional salt from each party involved in the compact block scheme.
Because we have a block header salt and a different (unique) per peer salt combined, any naturally ocurring collisions will happen only between some peers (one pair of peers, presumably) at any time. This has the effect that "blocks propagate around slowdowns" from these rare collisions.
BIP 152 Protocol flow⌗
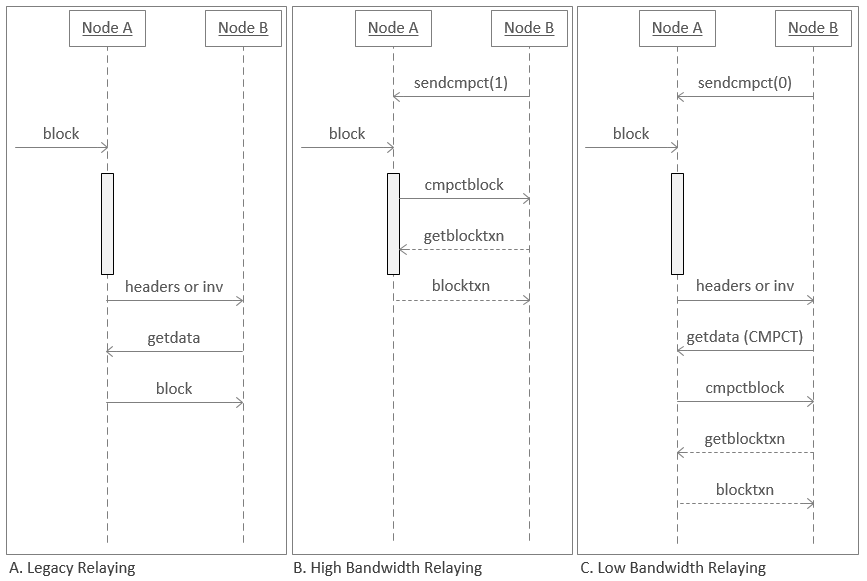
In both cases nodes have to start by first requesting compact blocks by sending a sendcmpct message which also indicates which "mode" they would like to operate under:
High-bandwidth (HB) mode⌗
A peer has to request HB mode, then when a block shows up, a compact_block is immediately sent, before validating the block first; it occurs at the same time that you’re validating the block (validation in the image is the sausage on the line), the reason it’s OK is because high-bandwidth mode is only used by full nodes who validate the block themselves before handing it out to any SPV clients.
Most of the time, that’s it — the protocol stops there (hence dashed lines after). If you’re missing some transactions you ask for the missing ones using the getblocktxn message, asking for transactions in postitions x, y, z. Remote then responds with blocktxn including the missing transactions.
One consequence of this mode is that if you’ve requested these from multiple (3 per the spec) peers then you might receive multiple copies, however this is not much of an issue with ~ 13compact blocks ≈ 40 kb/block.
Rationale:
-
Should negotiate high-bandwidth mode for last 3 peers that sent you a block
-
If you get a block from a different peer, you should negotiate HB mode with it and drop one of the other from HB mode
-
Allows a race between the fastest paths
-
Majority of the time recieve blocks from one of the last 3 who sent you one
Low-bandwidth (LB) relaying mode⌗
In LB mode, validation happens before any relaying of compact blocks. Node with a new block will send a headers or inv first announcing the new block, and when reciever requests the block with a getdata(CMPCT) the cmpctblock will be sent over, and again any missing transactions reconciled.
Rationale:
-
If blocks are sent without asking then bandwidth wasted when you recieve from multiple peers.
-
It does incur one extra round trip (and
inv)
Summary⌗
-
HB uses 0.5 to 1 round trips
-
LB uses 1.5 to 2.5 round trips
-
In all cases saves 99%+ of the block bandwidth
NoteThis is on the order of 12% of a nodes bandwidth, so 99% of 12% so 11.88% node bandwidth saved. -
Not much more room for reduction of the remaining 0.1% (fully optimised)
-
Latency-wise, 2.5 RTT can be a lot for a global link when TCP delays are factored in
-
Fast Block Relay Protocol showed it can be done in 0.5 RTT every time…
What about xthin?⌗
-
Unsalted 8-byte shortIDs (vulnerable)
-
Sends a bloom filter of the recievers mempool first which eliminates ~96% of
getblocktxn, but can’t do HB mode: It costs a constant 1 RTT + BW + CPU to save a RTT < 15% of the time. -
Not a useless idea for non-HB, but a lot more code surface for little gain.
-
Rushed into production and lead to at least 3 remote exploit crash bugs in BU.